
파이썬 사용중 판다스에서 엑셀파일 합치기를 하다보면 메모리 에러가 발생하는 경우가 있는데요.
판다스 데이터 용량 확인하기
먼저 판다스에서 info에 memory_usage 명령어를 사용해보면 데이터 용량을 확인할 수 있는데요.
df.info(memory_usage=True)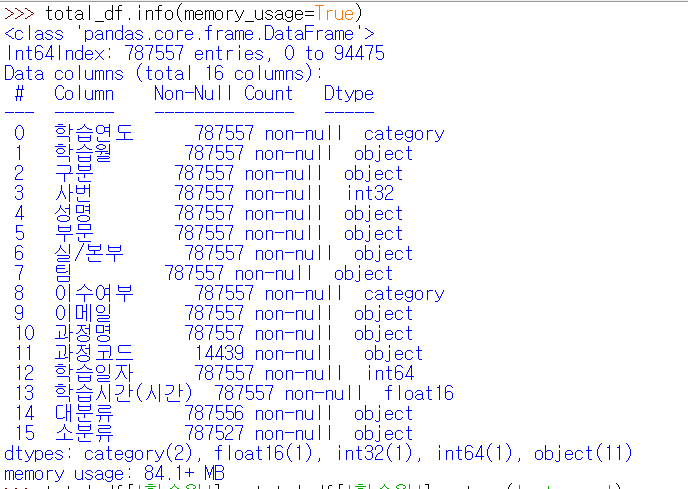
이때 파이썬 판다스의 데이터 종류가 있습니다. 바로 아래와 같은 데이터 형태가 있는데요.
판다스에서 파일을 옵션없이 불러오면 일반적으로 object로 불러옵니다. 하지만 이 object의 경우 아무 문자열이나 다 가능하기 때문에 데이터를 많이 사용하는데요.
| Pandas dtype | Python type | 데이터 형태 |
| object | str or mixed | 텍스트(문자열) 혹은 복합구성 |
| int64 | int | 정수 (integer numbers) |
| float64 | float | 실수 |
| bool | bool | 참/거짓 값(True/False) |
| datetime64 | – | 날짜와 시간 |
| timedelta[ns] | – | 두 시각의 차이 |
| category | – | 값이 유한개로 정해져있는 문자열값 |
판다스 데이터 양 줄이는 방법
바로 astype을 통해서 category로 변경하면 데이터를 줄일 수 있는데요.
df['학습월'] = df['학습월'].astype('category')
위처럼 몇개 항목 예를 들어 학습월 같이 12개 밖에 안되는 수치는 category로 변경했더니 10메가 이상 용량이 줄어들었습니다.
이 뿐만 아니라 파일을 불러올때, dtype 옵션을 통해서 아래처럼 카테고리로 변경하여 불러올수도 있습니다.
df = pd.read_excel('test.xlsx', dtype={'학습연도': 'category', '학습월': 'category','사번': 'int32', '부문': 'category' ,'실/본부':'category', '구분': 'category' })
그리고 또 합치는 방식에서도 변경을 줄 수 있는데요.
판다스 엑셀 데이터 합치는 방법
기본적으로 파일이 크지 않다면 아래처럼 간단한 for문을 통해서 반복해서 만들게 되는데요.
import pandas as pd, os
base_dir = 'some/dir/path'
total_df = pd.DataFrame() # 빈 DataFrame
for f_name in os.listdir(base_dir):
temp_df = pd.read_excel(os.path.join(base_dir, f_name))
total_df = total_df.append(temp_df) # 매 Loop에서 취해진 DataFrame을 앞서 정의한 빈 DataFrame에 붙임.하지만 이 방법은 매 루프에 데이터 프레임을 붙이게 되서 많은 리소스가 낭비됩니다.
즉 계속 루프가 돌아가게 되면 total_df라는 데이터 프레임이 커지게 되는 문제가 있습니다.
import collections as co
total = co.deque([])
for i, datapath in enumerate(files): # 굳이 enumerate를 안써도 됨.
print(i)
df = pd.read_excel(datapath)
try:
total.append(df) # list에 데이터셋을 넣어둠
print('finish ' + str(i) + 'th | datapath: ' + datapath)
except:
total_df = pd.concat(total)
total_df.to_excel('total.xlsx')
print('DataFrame append error!!!!')
break
total_df = pd.concat(total)
total_df.to_excel('total.xlsx')위처럼 For Loop에서 등장하는 DataFrame을 list에 담아 두고 마지막에 list 통째로 pd.concat()에 넣어 병합하는 방법으로 진행하는 것으로 속도를 빠르게 진행하는 형태가 됩니다.
실제로 이 방법으로 진행하니 메모리 사용량과 프로그램 실행 속도가 빨라졌습니다. 데이터가 연간으로 쌓이다 보니 약 100메가가 넘는데, 이 경우에 연초에는 문제가 없는 코드였지만 이제 11월까지 진행되니 코드 자체에서 문제가 발생하고 메모리 오류가 발생하더라구요.
혹시 동일한 문제를 겪으신다면 위의 방법으로 해결하시기 바랍니다.
그리고 위를 보시면 알겠지만 엑셀로 출력하는것보다 csv 파일로 출력하면 파일 용량은 크나 더 빠르게 출력할 수 있습니다.
이를 통해서 바로 엑셀 파일이 필요한 것이 아니라면 엑셀보다는 csv파일로 추출하는 것을 추천드립니다. 아래와 같은 코드를 통해 CSV 파일로 내려 받으면 더 빨리 진행할 수 있습니다.
df.to_csv('test.csv', index=True, encoding="utf-8-sig")아니면 excel의 경우 xlsxwriter, pyexcelerate을 쓰면 빨라진다고 하는데요. 패키지 설치후 시작하시면 됩니다. 실제로 두개를 다 써보니 pyexcelerate가 좀더 빠릅니다.
>pip install xlsxwriter
df.to_excel('test.xlsx', engine='xlsxwriter')
혹시 pyexcelerate를 사용한다면 아래의 형태로 사용하시면 됩니다.
from pyexcelerate import Workbook
values = [res_df.columns] + list(res_df.values)
wb = Workbook()
wb.new_sheet('sheet name', data=values)
wb.save('outputfile.xlsx')실제로 처리해야할 데이터 양이 커지게 된다면, 여러가지 방법을 고려해야 할 것 같네요. 연초에 문제없이 동작하던 코드가 왜 에러가 났는지 하나씩 살펴보니, 이런 메모리 문제가 있는줄 몰랐습니다.

실제로 파이썬의 메모리 사용량도 계속 증가하게 됩니다. 그래서 기존에는 발생하지 않던 문제가 발생하게 되는데요.
프로그램 짤때 이러한 점도 확인해야겠네요.